Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124



Modern IT environments are becoming increasingly complex as organizations continue adopting cloud computing, microservices, hybrid infrastructure, containers, and distributed applications. Traditional IT monitoring tools are no longer sufficient to manage these highly dynamic systems because they often provide limited visibility into application behavior, infrastructure performance, and user experience.
This is where observability plays a critical role. Observability helps IT teams gain deep insights into the internal state of systems by analyzing logs, metrics, traces, and real-time telemetry data. Instead of simply identifying that a problem exists, observability helps organizations understand why the issue occurred and how to resolve it quickly.
As businesses become more dependent on digital services, observability has become a foundational requirement for modern IT operations. It enables organizations to improve system reliability, reduce downtime, optimize performance, and deliver better customer experiences.
Observability refers to the ability to measure and understand the internal behavior of a system based on the data it generates. It allows IT teams to detect issues, troubleshoot problems, and monitor system health in real time.
Unlike traditional monitoring, which mainly focuses on predefined alerts and infrastructure metrics, observability provides a more comprehensive view of complex environments. It helps teams investigate unknown issues, identify root causes, and gain contextual insights into application and infrastructure performance.
Observability is typically built around three core components:
Together, these components provide complete visibility across systems, applications, and networks.
Many organizations confuse monitoring with observability, but they are not the same.
Monitoring focuses on tracking predefined metrics and generating alerts when thresholds are exceeded. It answers questions like:
Observability goes beyond monitoring by helping organizations understand why problems occur. It allows IT teams to explore unknown issues and investigate complex system behaviors.
For example, monitoring may detect that an application is slow, but observability helps identify whether the issue is caused by database latency, API failures, network congestion, or infrastructure bottlenecks.
In modern distributed environments, observability is essential because many issues cannot be predicted in advance.
As IT environments become more distributed and cloud-native, observability is becoming a critical operational capability.
Observability helps organizations detect issues before they impact users. Real-time telemetry data allows IT teams to identify unusual system behavior, performance degradation, or service disruptions early.
This proactive approach reduces downtime and minimizes operational risks.
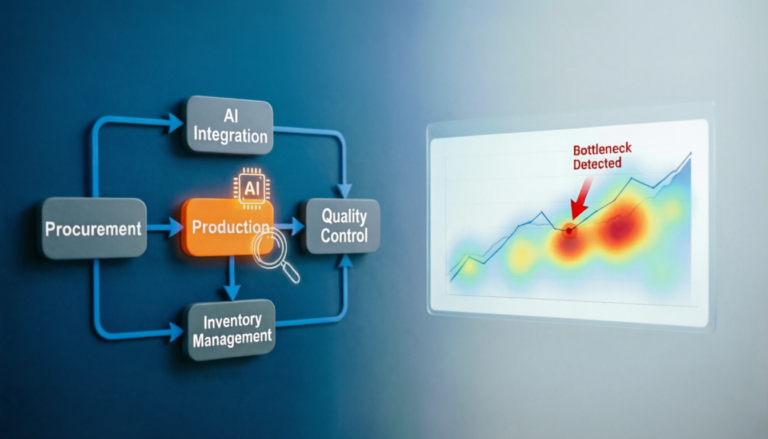
One of the biggest challenges in IT operations is identifying the root cause of issues quickly. Observability enables teams to trace requests across distributed systems and understand how components interact.
Instead of spending hours manually troubleshooting systems, IT teams can pinpoint problems faster using centralized observability platforms.
Observability provides detailed insights into application performance, response times, transaction flows, and infrastructure dependencies. This allows organizations to optimize performance and improve user experiences.
Businesses that rely heavily on digital services can use observability to ensure applications remain responsive and reliable.
Modern applications often run across multiple cloud environments, containers, APIs, and microservices. Traditional monitoring tools struggle to provide visibility across these distributed architectures.
Observability helps organizations understand how all system components interact, making it easier to manage complex environments.
Faster detection and root cause analysis significantly reduce MTTR. Organizations can resolve incidents more quickly, minimizing service disruptions and operational losses.
Lower MTTR directly improves service reliability and customer satisfaction.
Metrics are numerical measurements collected over time, such as CPU utilization, memory consumption, request latency, and network throughput.
Metrics help IT teams monitor system health and identify trends or anomalies.
Examples include:
Metrics provide high-level visibility into system performance.
Logs are detailed records of events generated by applications, servers, operating systems, and network devices.
Logs help teams investigate incidents and understand system behavior at a granular level.
Common log data includes:
Centralized log management is essential for effective observability.
Distributed tracing tracks requests as they move through different services and components within distributed systems.
Tracing helps organizations understand:
Tracing is particularly important in microservices architectures where applications rely on multiple interconnected services.
Cloud-native technologies such as Kubernetes, containers, and serverless computing have transformed IT infrastructure. However, these environments are highly dynamic and difficult to monitor using traditional approaches.
Observability helps organizations manage cloud-native systems by providing real-time visibility into:
Without observability, troubleshooting cloud-native environments becomes extremely difficult.
Modern observability platforms increasingly use artificial intelligence and machine learning to improve operational efficiency.
AI-powered observability solutions can:
Automation allows IT operations teams to respond faster to incidents and reduce manual workload.
AIOps (Artificial Intelligence for IT Operations) is becoming a major trend in enterprise observability strategies.
Observability is not only a technical advantage but also a business enabler. Organizations that invest in observability gain several strategic benefits.
Application downtime and performance issues directly impact customer satisfaction. Observability helps ensure reliable digital experiences.
IT teams spend less time troubleshooting and more time focusing on innovation and strategic projects.
Continuous visibility into systems improves infrastructure stability and reduces unexpected outages.
Observability supports cloud adoption, DevOps practices, and modern application development initiatives.
Shared observability platforms improve collaboration between development, operations, security, and engineering teams.
Although observability provides significant benefits, organizations may face implementation challenges.
Modern systems generate massive amounts of telemetry data, making storage and analysis difficult.
Many organizations use multiple disconnected monitoring and logging tools, creating operational silos.
Effective observability requires expertise in cloud infrastructure, distributed systems, data analytics, and automation.
Collecting and storing observability data at scale can become expensive if not managed properly.
Organizations must develop clear observability strategies to overcome these challenges.
Organizations can maximize observability success by following several best practices.
Consolidate logs, metrics, and traces into unified observability platforms for better visibility.
Real-time insights help organizations respond to incidents faster.
Automation reduces operational workload and improves response times.
Using open observability frameworks improves flexibility and vendor interoperability.
Dashboards should provide actionable insights rather than excessive data.
Observability should be embedded into software development and deployment processes.
Observability will continue evolving as organizations adopt increasingly complex digital infrastructures. Future observability trends may include:
As digital ecosystems expand, observability will become even more essential for maintaining performance, resilience, and operational efficiency.
Observability has become a critical capability in modern IT operations. As organizations adopt cloud-native technologies, distributed architectures, and digital transformation strategies, traditional monitoring approaches are no longer sufficient to manage system complexity.
By providing deep visibility into metrics, logs, and distributed traces, observability helps organizations detect issues faster, reduce downtime, improve application performance, and strengthen operational resilience. It enables IT teams to move from reactive troubleshooting to proactive system optimization.
Beyond technical benefits, observability also delivers significant business value by improving customer experiences, supporting innovation, and accelerating digital transformation initiatives.
Organizations that invest in strong observability practices today will be better prepared to manage the increasingly dynamic and data-driven IT environments of the future.